ここから本文です。
株式会社 Geek Guild(京都企業紹介)
知恵の経営、元気印、経営革新、チャレンジ・バイの各認定等を受けた府内中小企業を紹介するページです。




「my 薬剤師(TM)」薬局向けサービス「薬剤監査アプリ」まもなくリリース
(2024年1月17日、ものづくり振興課 足利)
株式会社 Geek Guild(外部リンク)(京都市)による、薬局の作業効率化、患者の利便性向上の双方を追求する「my 薬剤師(TM)」。令和5年スマートプロダクト認定(外部リンク)も受けました。
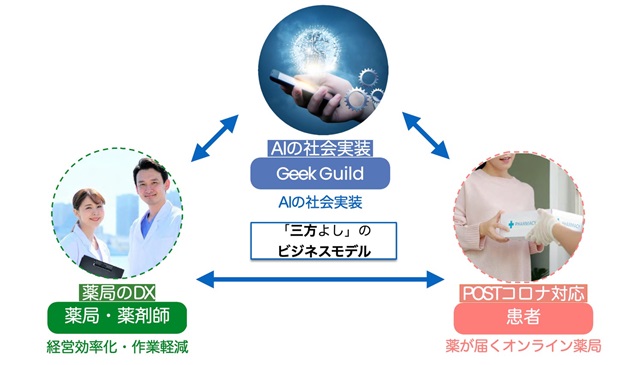
そのうち、薬局向けサービス「薬剤監査アプリ」がまもなくリリースです!

「薬剤監査」とは、調剤した薬剤が処方箋に記載した薬剤と合致しているかを確認する、薬剤師の作業です。「薬剤監査アプリ」は、処方せんのQRコードで処方せんの情報を読み取り、薬剤の画像をスマホで撮影して、薬剤の名前を読み取り処方せんの情報と照合するAI搭載アプリです。
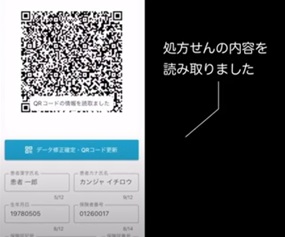

薬局・薬剤師の職場は忙しく、患者を待たせることがストレスになるので、通常、画像認識で30秒はかかるのを2秒から3秒でやってほしいというハードルの高い要望があったそう。しかし、AIの速度を上げるためには、サーバーのマシンパワーを使うことになり、提供価格が上がるというジレンマがあったそう。そこで、AIやデータベースなどに最先端の技術を導入しながらも、最低限のAI機能に絞ることで、ご利用しやすい価格に落としていったとのこと。
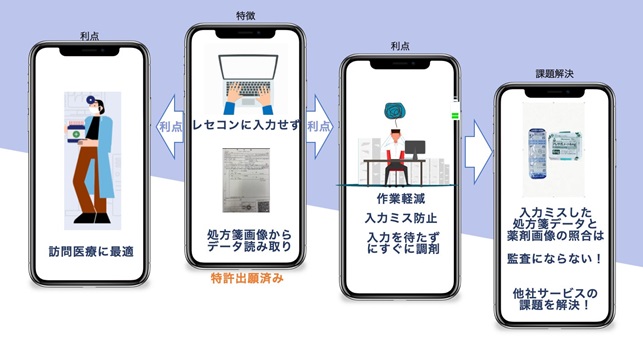
また、薬局内のレセコン(レセプトコンピュータのこと。医療機関が健康保険組合に医療費を請求するために診療報酬明細書を作成するシステム)にとらわれないシステム・アプリとすることで、訪問医療の現場でも使えるなど、将来拡張する個人向け、さらには病院向けサービスのことも踏まえた仕様とされているそうです。
CRCC Asia・京都府「米国大学生インターンプロジェクト」
(2023年7月10日、ものづくり振興課 足利)

薬剤師を探すWebアプリ「my薬剤師(外部リンク)」
|
薬剤師を探すWebアプリ「my薬剤師(外部リンク)」を公開
「自分にあう薬剤師さんを探したい」「お薬を送ってほしい」にこたえる、薬局ではなく薬剤師を探すWebアプリ(外部リンク)です。
|

高品質で開発負担を抑えるAIを!「SmallTrain」と「キャッシュAI」
(令和3年12月21日、ものづくり振興課 足利)

株式会社 Geek Guild(外部リンク)(京都市)の取組紹介です。
高精度な学習済みAIモデルを使って、無料・スモールデータで独自AIを開発できる「SmallTrain(外部リンク)」
AIモデルをつくる方法は大きく3つあります。1つは、アルゴリズムや数学的関数を理解して、それをプログラミングによりAIモデルを自作する、2つ目は、アルゴリズム、数学的関数はTensorFlowなどの計算ライブラリを用いて、モデルを自作する、3つ目は、計算ライブラリを呼び出すのにラッパーを用いて、簡単にモデルを作成するというものです。その中で、「SmallTrain」は、ライブラリでもありラッパーでもあります。独自の関数を用いて、60階層以上のニューラルネットワークを構築するとともに、画像データ、時系列データなど様々なデータで学習済みであるため、ユーザーの手持ちのスモールデータで独自の学習済みモデルが無料で構築できます。
SmallTrainを活用することで、様々な「画像認識」はもちろん、客室価格予測(ダイナミックプライシング)、発電・消費電力予測、工場の異常検知などの「時系列予測」、ロジスティックの発注自動化、売上最大化ホテル客室予約などの「強化学習」などを行えます。
高価なGPUやAIチップなしに小型端末で動作し、開発コストを抑える「キャッシュAI」
「クラウドAI」は、インターネットに常時接続し、何よりサーバーが必要です。一方「エッジAI」は、ソースコードを提供するので、リバースエンジニアリング等の恐れがあり、提供価格が高止まりする傾向があるのだそう。そこで考えられたのが同社の「キャッシュAI」。高価なGPUやAIチップなしでスマホやスマートウォッチなどの小型端末に搭載できます。開発者は、ダウンロードすることで安価に開発ができ、しかも暗号化技術を用いているので、リバースエンジニアリングのリスクから解放されます。

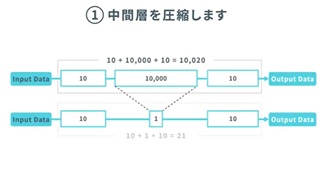
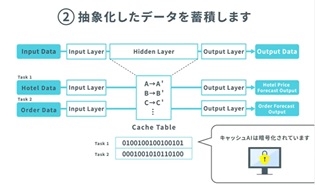
なぜ、小型デバイスに搭載できるのか。ディープラーニングのAIモデルは、大きいもので100階層ほどのニューラルネットワークの階層構造になっています。その階層は入力層、中間層、出力層とで区分され、そのもっとも大きい中間層をおよそ1階層分ほどに変換したものが「キャッシュAI」です。例えば、SmallTrainで作成した学習済みモデルの中間層は60階層以上ですが、キャッシュAIは、その中間層を1階層分ほどに変換しているのです。AIの高速化、軽量化ができ、従来は必須とされているGPUがなくても予測等ができるのです。
現在、これらを用いて、地域に親しまれるまちの薬局屋さんとの共同開発など、ユーザーに優しい開発が進んでいます。



(左)「さぎの森薬局」の皆様と。(右)“京都の太陽光発電所”AI無料診断(外部リンク)
世界を制するオープンソースAIライブラリ「SmallTrain」
(掲載:令和2年4月15日、聞き取り:令和2年2月、ものづくり振興課 足利)
株式会社 Geek Guild(外部リンク)(京都市)の尾藤代表取締役副社長 COOにお話をおうかがいしました。
オープンソースAIライブラリ「SmallTrain」
--別のAI企業を経営されてらっしゃった頃からのお付き合いですが、改めて御社の概要を教えてください。
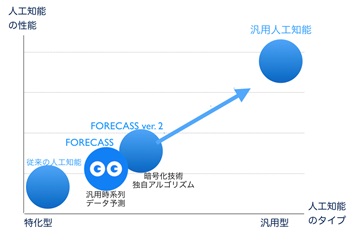
尾藤)「汎用人工知能」の開発をめざす組織として2018年に設立しました。社名は、米国の優秀なAIエンジニアが自らをGeek(ギーク)と呼称していることから、最先端のAI技術を提供できる高度なAI研究開発ギルド(組織)という意味です。
--「汎用人工知能」というのは?
尾藤)特化型の人工知能ではなく、それらを作るAIベンダー、エンジニア向けの機械学習フレームワークとでも言いましょうか。「FORECASS」として親しんでいただいてましたが、「SmallTrain」と名称変更、リニューアルし、オープンソースで提供します。具体的に言いますと、Pythonで書かれたオープンソースのニューラルネットワークライブラリです。TensorFlowまたはPyTorchの上で実行できます。ディープニューラルネットワークでの高速実行を可能にするように設計されており、プロのエンジニア向けのツールとして、ユーザーフレンドリーでモジュール式、拡張可能であることに焦点を当てています。
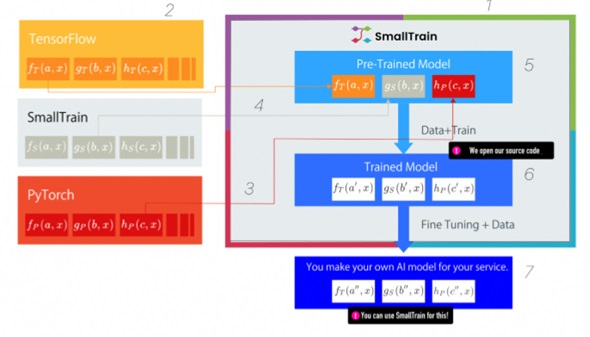
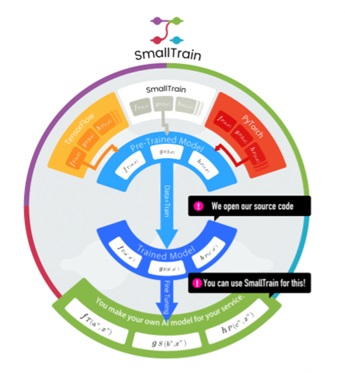
図「SmallTrainの機能と構造」
--SmallTrainという名称の意味は何ですか?
尾藤)ビッグデータではなく、スモールデータでいい、という意味での「Small」と、「Train」は訓練、学習ということですね。学習済みモデルとしては、グローバル企業が既に出していますが、それを凌駕する性能と、それでいて使いやすいものになっています。
AI構築が早くてラク、データは手持ちのものでいい、ハードウェアも特別なもの不要
--スモールデータでいい?学習済みモデル?
尾藤)通常、AIの構築には、学習データを入力しパラメータをチューニングする際の専門的な知識、手間とコストが必要で、AIベンダーの仕事の負荷はそこにあります。
--私の安易な理解では、機械学習では、人が定義したデータの特徴から関数(法則)を生成する「法則の自動化」が行われ、ディープラーニングでは、データの特徴の定義をも自動化する、「特徴法則化の自動化」が行われていると思うのですが、とはいえ、機械様にデータの特徴を見出してもらえるように、人間が多層構造のニューラルネットワークを組んで、微分や線形代数など高度な数学知識を駆使して、かなりのお膳立てをしているように思います。
尾藤)そのとおりですね。加えて、AIにデータを入力して学習させるためにはGPUを使った高速処理が必要です。
--なるほど、そうですね。
尾藤)しかし、SmallTrainでは、ユーザー様がお持ちのデータを学習させ、その分野のAIプログラムとして構築していっていただくものではありますが、ベースの部分は、既に学習し終えていて、例えば60ピラミッド階層ものニューラルネットワーク構造を構築済みです。
--そうなのですね。
尾藤)従いまして、まず、AIにデータを学習させる⼿間とコストを大幅に削減でき、あとは簡単な作業のみで、しかも画面で簡単に操作できるものです。また、ビッグデータは必要なく、データ収集のための膨大な時間とコストを省けます。さらには、短期間に開発ができるので開発コストがぐんと下がりますし、計算処理を⾼速化できるアルゴリズムを搭載しており、特別なハードウェアも不要です。

異常検知、薬剤検知、エネルギー需給予測、ダイナミックプライシング、ロジステック自動発注
--どういったAI構築に利用されているのでしょうか?
尾藤)当社自身がSmallTrainを用いて開発したものとしては、例えば、生産工程の異常検知ですね。お手持ちのデータを最大限に生かし少ないデータで検知できる技術があるため、センサーで追加のデータ収集をお願いすることが原則ありません。大手企業の工場ラインの設備で少ないデータからの異常検知のPoCを実施されています。

--なるほど。
尾藤)あるいは、調剤薬局の薬剤監査システムAIなどございますよ。薬局で薬を調合される際に、薬剤師の調合が処方箋通りかどうかを画像認識で監査するシステムなのですが、既存のシステムでは大きな機材が必要なため、SmallTrainで、低コストで監査精度99%以上、1秒1監査という高精度・高性能を実現しました。粉薬の小さな粒でも正確に判別できるのです。
--すごいですね。
尾藤)さらには、エネルギー関連ですね。発電量と消費量を予測し、効率の良いエネルギー循環をつくります。SmallTrainで需要と供給の値を予測すると、発電事業の売電計画が立案しやすくなります。また、発電量の予測値と実測値の乖離により、発電所の不具合の発見にもつながり、発電所のO&M事業にも役立っています。SmallTrainの発電予測は平均二乗誤差率が1%未満という世界トップ水準の精度なので、実践の発電事業のエネルギーマネージメントEMSに利用できるのです。これまで、新電力事業における売電収入アップ等にも貢献してまいりました。

--いいですね。
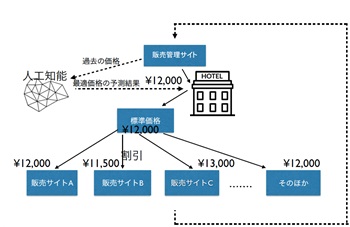
尾藤)あるいは、販売価格の最適化やダイナミックプライシングです。時間ごとに変動のある価格の予測はたいへんな作業です。しかも、他社との競争のなか最適値を割り出すのは人間には至難の技です。SmallTrainは、需要と供給のバランスを考慮し、競合他社の価格と比較し、その上で、売上を最大化にするために最適な価格を予測します。例えば「ホテルの客室」の価格決定にSmallTrainを利用しました。ホテル予約は1ヶ月前からが重要です。客室の予約状況は、ホテル客室予約サイトの価格に、大きく影響されます。良い値付けをすることでホテルは営業利益を最大化できます。様々な予約サイトから上がってくるデータを元に、安すぎず利益が大きくなる値付けを提供します。ホテル市場には予約・販売サイトがたくさんあり、各サイトごとにセール価格を設定するため、実際にお客様が支払った価格が、ホテルの卸価格とそれぞれ異なります。実質、ホテル側には“日毎の客室価格の卸価格”と予約サイトから送られてきた“お客様が支払った(家族分の)合計価格”しかない場合がありました。それでも、追加にデータ収集を依頼せず、“今ある価格データ”で予測を提供いたしました。
--素晴らしいですね。学習方法は、教師あり学習?
尾藤)異常検知、薬剤検知等は「教師あり学習」ですが、「強化学習」によるものもありますよ。例えば、ロジステック自動発注というものでして、ある企業の倉庫から各店舗への配送の回数を極力減らすことを目指すことを目的に、倉庫への発注のタイミング、商品ごとに箱の大きさが違うわけですが、そうした容積などを勘案し、トラックにどう効率的にタイミングを合わせて発注するか、といった、もはや人の頭ではどう計算していいのかわからないようなことに「答」を示してくれます。
--おもしろいですね!しかし、他のAIベンダーに対しても、オープンソースなのですよね。AIベンダーが喜ぶ技術的な点は他にもありますか?
尾藤)はい。昨今では学習済みモデルが色々と公開されています。ただ、それらはほとんどが研究やPoCに適しているが、実運用には使いにくいということがあります。SmallTrainは商用での実運用に利用してきた学習済みモデルを公開しますので、商用のためのAIモデル構築を考えるプロ向けになります。だからビッグデータがなくともできる、マシンパワーを使わずにできるということにこだわり、実運用の際のコスト削減に注力しています。
--そのほか、具体的な事柄を少し説明してください。
尾藤)はい。少し技術的な話で恐縮ですが、SmallTrainはGoogleのTensorFlowだけでなく、FacebookのPyTorchにも対応していきます。どちらのライブラリから関数を呼び出すことができます。これがラッパーといって、すでにあるライブラリから関数を呼びだし、高い数学的知見を用いなくてもAIモデルをつくることができるSmallTrainの1つ目の特徴です。(図「SmallTrainの機能と構造」の1の部分)
--なるほど、GoogleやFacebookの両方のライブラリがつかえるのですね。
尾藤)ライブラリに関しては、SmallTrain自体も関数(数学的な)ライブラリをもっています。最新論文が発表されるたびに自社内で検証をし、有効なアルゴリズムは取り入れるようにしています。この作業は数学的な知識と、英語論文の読解力、それに書かれているアルゴリズムを実装するプログラミング能力が必要ですので、大変な作業と言えます。これをいち早く行い、ライブラリにしていきます。SmallTrainを使うと最先端のアルゴリズムを利用できるようになります。(図「SmallTrainの機能と構造」の3の部分)
--英語の論文を読んで、プログラミングするのは大変そうなので、SmallTrainがやってくれるなら、それはいいですね。
尾藤)ええ。それに、自社内で開発したアルゴリズムやノウハウをたくさん盛り込んでいますので、それもオープンにしています。
まだ準備中で完全なオープンソースではないのですが、少しずつオープンソース化を進めていきます。
今後、ますます楽しみですね!
お問い合わせ